Search AI Products and News
Explore worldwide AI information, discover new AI opportunities
- ✓AI News
- AI Tools
2025-01-20 17:54:54.AIbase.
Breakthrough in Large Models: Extracting High-Quality Multimodal Textbooks from Educational Videos

2024-08-12 14:59:02.AIbase.
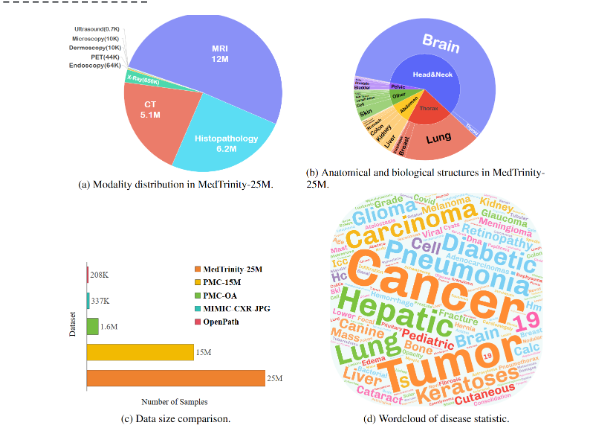
MedTrinity-25M: A Medical Multimodal Dataset Containing 25 Million Medical Images
2023-10-07 15:48:13.AIbase.